You might have interacted with ChatGPT in some way. Whether you have asked for help in teaching a particular concept or a detailed guided step to solve a complex problem.
In between, you have to provide a “prompt”(short or long) to communicate with the LLM to produce the desired response. However, the true essence of these models is not just in their architecture, but in how intelligently we communicate with them.
This is where prompt engineering techniques start to happen. Continue reading this blog to learn about what prompt engineering is, its techniques, key components, and a hands-on practical guide on building an LLM using prompt engineering.
What is Prompt Engineering?
To understand prompt engineering, let’s break down the term. The “prompt” refers to a text or sentence that LLM intakes as NLP and generate output. The response could be recursive, iterative, or incomplete.
Therefore, prompt engineering comes into the picture. It refers to crafting and optimising prompts to generate an iterative response. These responses satisfy the problem or generate output based on the objective desired, hence controllable output generation.
With prompt engineering, you are pushing an LLM into a definitive direction with an improved prompt to generate an effective response.
Let’s understand with an example.
Prompt Engineering Example
Imagine yourself as a tech news writer. Your responsibilities include researching, crafting, and optimizing tech articles with a focus on ranking in search engines.
So, what’s a basic prompt you would give to an LLM? It could be like this:
“Draft an SEO-focused blog post on this “title” including a few FAQs.“
It could generate a blog post on the given title with FAQs, but they lack factual, reader’s intent, and content depth.
With prompt engineering, you can tackle this situation effectively. Below is an example of a prompt engineering script:
Prompt: “You are an expert SEO content editor. Your task is to generate a fully structured, SEO-optimized blog post from a given title.
Title: “Mention topic here”
Instructions:
– Write a 1500+ word blog post with SEO best practices.
– Include meta title, meta description, introduction, structured headings (H2/H3), conclusion, and FAQs.
– Use clear, engaging, fact-based writing.
– Naturally optimize for SEO without keyword stuffing.“
The difference between these two prompts is the iterative response. The first prompt may fail to generate an in-depth article, keyword optimisation, structured clarity content, etc., while the second prompt intelligently fulfils all the goals.
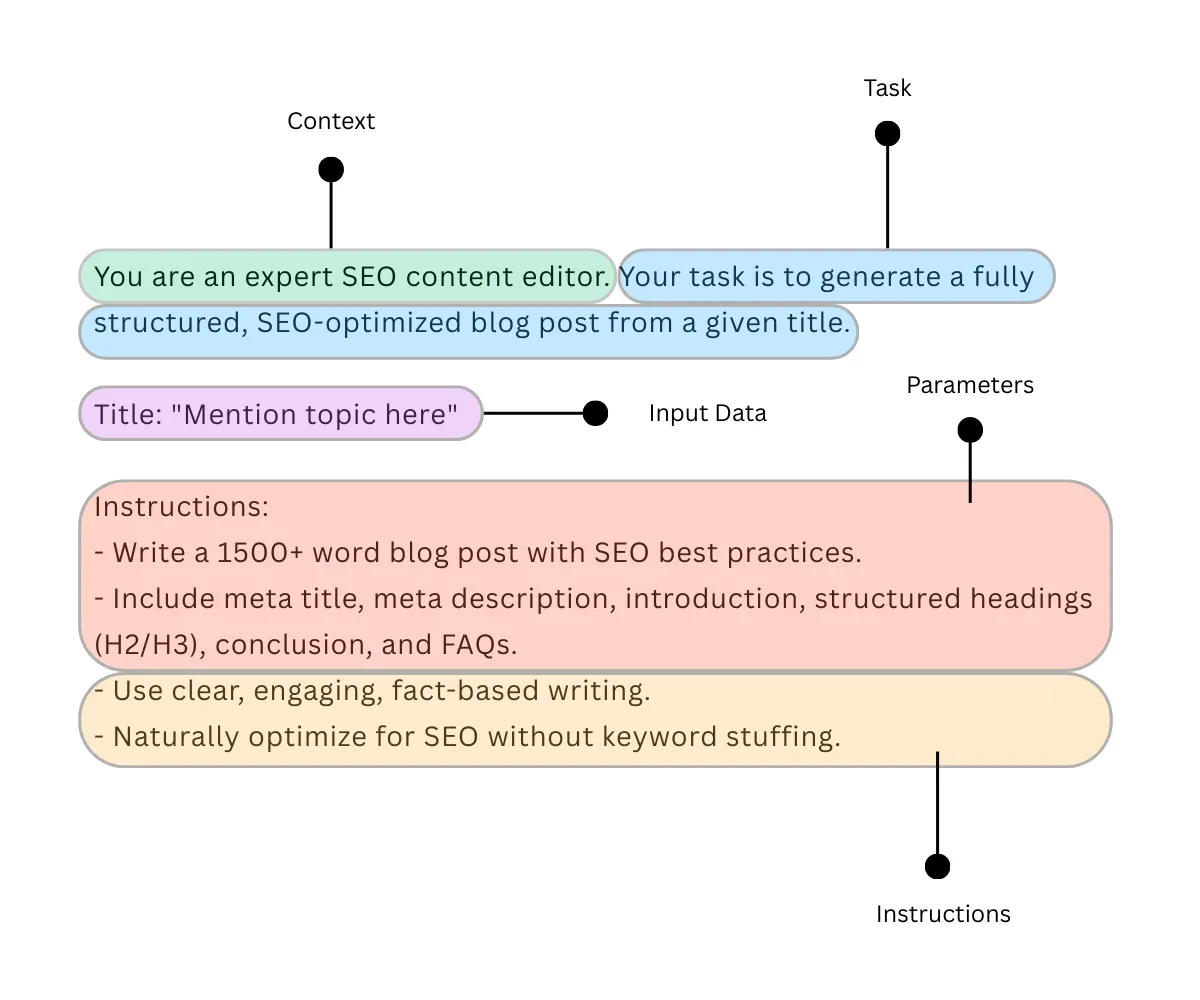
Components Of Prompt Engineering
You might have observed crucial things earlier. When optimising for prompt, we define the task, give instructions, add context, and parameters to give an LLM a directive approach for output generation.
Critical components of prompt engineering are as follows:
- Task: In a statement form that a user specifically defines.
- Instruction: Provide necessary information to complete a task in a meaningful manner.
- Context: Adding an extra layer of information to acknowledge by LLM to generate a more relevant response.
- Parameters: Imposing rules, formats, or constraints for the response.
- Input Data: Provide the text, image, or other class of data to process.
The output generated by an LLM from a prompt engineering script can further be optimised through various techniques. There are two classifications of prompt engineering techniques: basic and advanced.
For now, we’ll discuss only basic prompt engineering techniques for beginners.
Prompt Engineering Techniques For Beginners
I have explained seven prompt engineering techniques in a tabular structure with examples.
| Techniques | Explanation | Prompt Example |
|---|---|---|
| Zero-Shot Prompting | Generating output by LLM without any examples given. | Translate the following from English to Hindi. “Tomorrow’s match will be amazing.” |
| Few-Shot Prompting | Generating output by an LLM by learning from a few sets of example ingestion. | Translate the following from English to Hindi. “Tomorrow’s match will be amazing.” For example: Hello → नमस्ते All good → सब अच्छा Great Advice → बढ़िया सलाह |
| One-Shot Prompting | Generating output by an LLM learning from a one-example reference. | Translate the following from English to Hindi.“Tomorrow’s match will be amazing.” For example: Hello → नमस्ते |
| Chain-of-thought (CoT) Prompting | Directing LLM to break down reasoning into steps to improve complex task performance. | Solve: 12 + 3 * (4 — 2). First, calculate 4 — 2. Then, multiply the result by 3. Finally, add 12. |
| Tree-of-thought (ToT) Prompting | Structuring the model’s thought process as a tree to know the processing behavior. | Imagine three economists trying to answer the question: What will be the price of fuel tomorrow? Each economist writes down one step of their reasoning at a time, then proceeds to the next. If at any stage one realizes their reasoning is flawed, they exit the process. |
| Meta Prompting | Guiding a model to create a prompt to execute different tasks. | Write a prompt that helps generate a summary of any news article. |
| Reflexion | Prompting to instruct the model to look at past responses and improve responses in the future. | Reflect on the mistakes made in the previous explanation and improve the next one. |
Now that you have learned prompt engineering techniques, let’s practice building an LLM application.
Building LLM Applications Using Prompt Engineering
I have demonstrated how to build a custom LLM application using prompt engineering. There are various ways to accomplish this. But I kept the process simple and beginner-friendly.
Prerequisites:
- An operating system with a minimum of 8GB VRAM
- Download Python 3.13 on your system
- Download and install Ollama
Objective: Creating “SEO Blog Generator LLM” where the model takes a title and produces an SEO-optimized blog draft.
Step 1 – Installing The Llama 3:8B Model
After confirming that you have satisfied the prerequisites, head to the command line interface and install the Llama3 8b model, as this is our foundational model for communication.
ollama run llama3:8b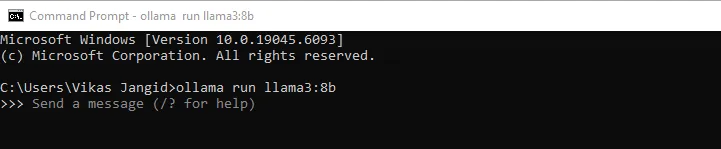
The size of the LLM is approximately 4.3 Gigabytes, so it might take a few minutes to download. You would see a success message after download completion.
Step 2 – Preparing Our Project Files
We will require a combination of files for communicating with the LLM. It includes a Python script and a few requirements files.
Create a folder and name it “seo-blog-llm” and create a requirements.txt file with the following and save it.
ollama>=0.3.0
python-slugify>=8.0.4Now, head to the command line interface and at the project source path, run the following command.
pip install -r requirements.txt
Step 3 – Creating Prompt File
In sublime editor or any code-based editor, save the following code logic with the file name prompts.py. This logic guides the LLM in how to respond and produce output. This is where prompt engineering shines.
SYSTEM_PROMPT = """You are an expert SEO content editor. You write fact-aware, reader-first articles that rank.
Follow these rules strictly:
- Output ONLY Markdown for the final article; no explanations or preambles.
- Include at the top a YAML front matter block with: meta_title, meta_description, slug, primary_keyword, secondary_keywords, word_count_target.
- Keep meta_title ≤ 60 chars; meta_description ≤ 160 chars.
- Use H2/H3 structure, short paragraphs, bullets, and numbered lists where useful.
- Keep keyword usage natural (no stuffing).
- End with a conclusion and a 4–6 question FAQ.
- If you insert any statistic or claim, mark it with [citation needed] (since you’re offline).
"""
USER_TEMPLATE = """Title: "{title}"
Write a {word_count}-word SEO blog for the above title.
Constraints:
- Target audience: {audience}
- Tone: simple, informative, engaging (as if explaining to a 20-year-old)
- Geography: {geo}
- Primary keyword: {primary_kw}
- 5–8 secondary keywords: {secondary_kws}
Format:
1) YAML front matter with: meta_title, meta_description, slug, primary_keyword, secondary_keywords, word_count_target
2) Intro (50–120 words)
3) Body with clear H2/H3s including the primary keyword naturally in at least one H2
4) Practical tips, checklists, and examples
5) Conclusion
6) FAQ (4–6 Q&As)
Rules:
- Do not include “Outline” or “Draft” sections.
- Do not show your reasoning or chain-of-thought.
- Keep meta fields within limits. If needed, shorten.
"""Step 4 – Setting Up Python Script
This is our master file, which acts as a mini application for communicating with the LLM. In sublime editor or any code-based editor, save the following code logic with the file name generator.py.
import re
import os
from datetime import datetime
from slugify import slugify
import ollama # pip install ollama
from prompts import SYSTEM_PROMPT, USER_TEMPLATE
MODEL_NAME = "llama3:8b" # adjust if you pulled a different tag
OUT_DIR = "output"
os.makedirs(OUT_DIR, exist_ok=True)
def build_user_prompt(
title: str,
word_count: int = 1500,
audience: str = "beginner bloggers and content marketers",
geo: str = "global",
primary_kw: str = None,
secondary_kws: list[str] = None,
):
if primary_kw is None:
primary_kw = title.lower()
if secondary_kws is None:
secondary_kws = []
secondary_str = ", ".join(secondary_kws) if secondary_kws else "n/a"
return USER_TEMPLATE.format(
title=title,
word_count=word_count,
audience=audience,
geo=geo,
primary_kw=primary_kw,
secondary_kws=secondary_str
)
def call_llm(system_prompt: str, user_prompt: str, temperature=0.4, num_ctx=8192):
# Chat-style call for better instruction-following
resp = ollama.chat(
model=MODEL_NAME,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
options={
"temperature": temperature,
"num_ctx": num_ctx,
"top_p": 0.9,
"repeat_penalty": 1.1,
},
stream=False,
)
return resp["message"]["content"]
def validate_front_matter(md: str):
"""
Basic YAML front matter extraction and checks for meta length.
"""
fm = re.search(r"^---\s*(.*?)\s*---", md, re.DOTALL | re.MULTILINE)
issues = []
meta = {}
if not fm:
issues.append("Missing YAML front matter block ('---').")
return meta, issues
block = fm.group(1)
# naive parse (keep simple for no dependencies)
for line in block.splitlines():
if ":" in line:
k, v = line.split(":", 1)
meta[k.strip()] = v.strip().strip('"').strip("'")
# checks
mt = meta.get("meta_title", "")
mdsc = meta.get("meta_description", "")
if len(mt) > 60:
issues.append(f"meta_title too long ({len(mt)} chars).")
if len(mdsc) > 160:
issues.append(f"meta_description too long ({len(mdsc)} chars).")
if "slug" not in meta or not meta["slug"]:
# fall back to title-based slug if needed
title_match = re.search(r'Title:\s*"([^"]+)"', md)
fallback = slugify(title_match.group(1)) if title_match else f"post-{datetime.now().strftime('%Y%m%d%H%M')}"
meta["slug"] = fallback
issues.append("Missing slug; auto-generated.")
return meta, issues
def ensure_headers(md: str):
if "## " not in md:
return ["No H2 headers found."]
return []
def save_article(md: str, slug: str | None = None):
if not slug:
slug = slugify("article-" + datetime.now().strftime("%Y%m%d%H%M%S"))
path = os.path.join(OUT_DIR, f"{slug}.md")
with open(path, "w", encoding="utf-8") as f:
f.write(md)
return path
def generate_blog(
title: str,
word_count: int = 1500,
audience: str = "beginner bloggers and content marketers",
geo: str = "global",
primary_kw: str | None = None,
secondary_kws: list[str] | None = None,
):
user_prompt = build_user_prompt(
title=title,
word_count=word_count,
audience=audience,
geo=geo,
primary_kw=primary_kw,
secondary_kws=secondary_kws or [],
)
md = call_llm(SYSTEM_PROMPT, user_prompt)
meta, fm_issues = validate_front_matter(md)
hdr_issues = ensure_headers(md)
issues = fm_issues + hdr_issues
path = save_article(md, meta.get("slug"))
return {
"path": path,
"meta": meta,
"issues": issues
}
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Generate SEO blog from title")
parser.add_argument("--title", required=True, help="Blog title")
parser.add_argument("--words", type=int, default=1500, help="Target word count")
args = parser.parse_args()
result = generate_blog(
title=args.title,
word_count=args.words,
primary_kw=args.title.lower(), # simple default keyword
secondary_kws=[],
)
print("Saved:", result["path"])
if result["issues"]:
print("Validation notes:")
for i in result["issues"]:
print("-", i)Just to ensure you’re doing right. Your project folder should have the following files. Note that the output folder and the _pycache_ folder will be created explicitly.
Step 5 – Run It
You are almost done. In the command line interface, run the following command to get the output. An output will automatically get saved in the output folder of your project source in the (.md) format file.
python generator.py --title "Luxury Interior Design Ideas for Villas & Resorts" --words 1800And you would see something like this in the command line:

To open the generated output markdown (.md) file. Either use VS Code or drag-and-drop to any browser. Here, I have used the Chrome browser to open the file, and the output looks acceptable:
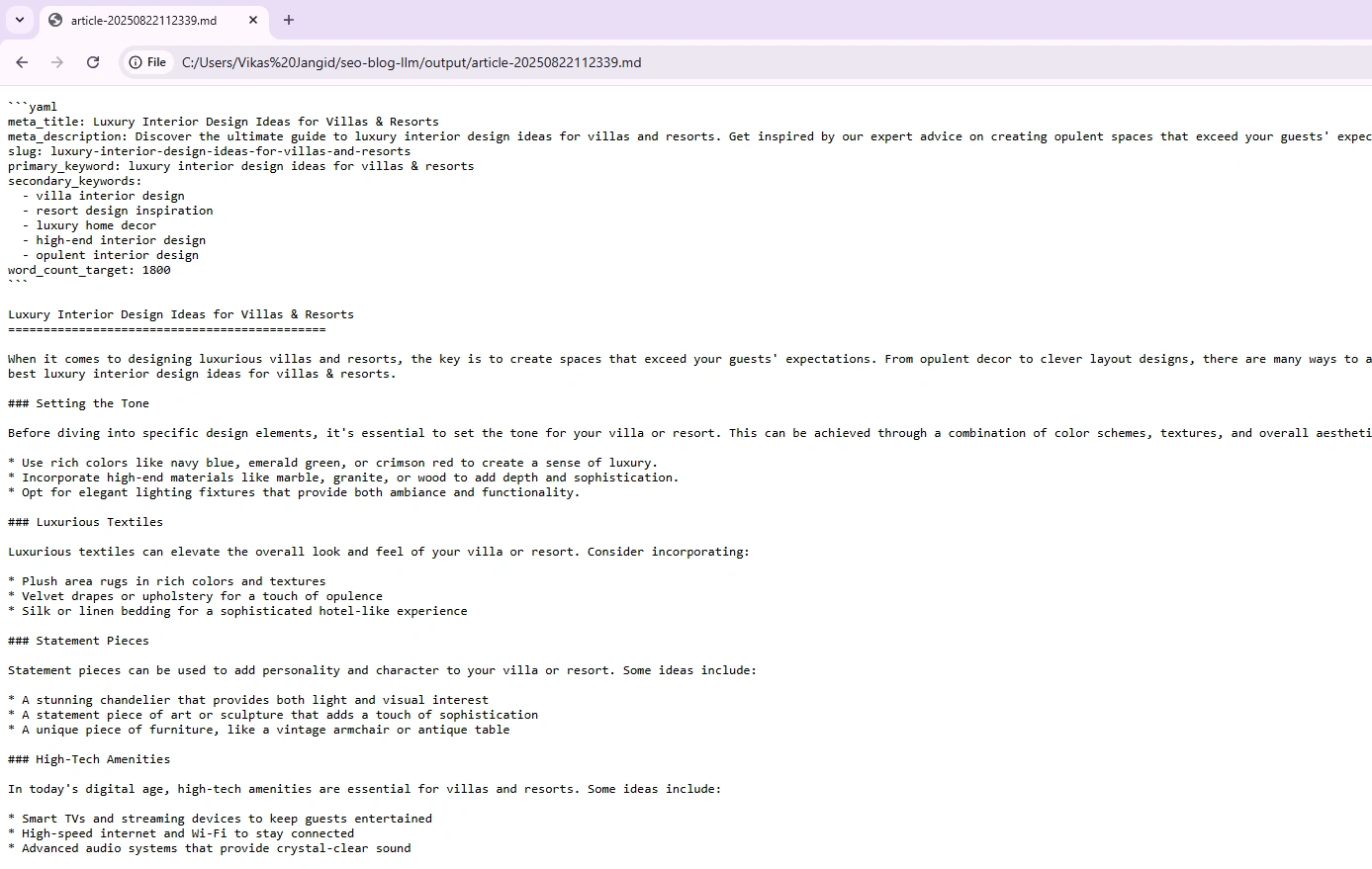
Things to keep in mind
Here are a few things to keep in mind while using the above code:
- Running the setup with only 8 GB RAM led to slow responses. For a smoother experience, I recommend 12–16 GB RAM when running LLaMA 3 locally.
- The model LLama3:8B often returned fewer than the requested words. The generated output is fewer than 800 words.
- Add passing parameters like
geo,tone, andtarget audiencein the run command to generate more specified output.
Key Takeaway
You’ve just built a custom LLM-powered application on your own machine. What we did was use the raw LLaMa 3 and shaped its behavior with prompt engineering.
Here’s a quick recap:
- Installed Ollama that lets you run LLaMA 3 locally.
- Pulled the LLaMA 3 8B model so you don’t rely on external APIs.
- Wrote prompt.py that defines how to instruct the model.
- Wrote generator.py that acts as your mini app.
In the end, you have learned prompt engineering concept with its techniques and hands-on practice developing an LLM-powered application.
Read more:
Frequently Asked Questions
A. LLMs cannot generate output explicitly and therefore require a prompt that guides them to understand what task or information to produce.
A. Prompt engineering instructs LLM to behave logically and effectively before producing the output. It means crafting specific and well-defined instructions to guide the LLM in generating the desired output.
A. The four pillars of prompt engineering are Simplicity (clear and easy), Specificity (concise and specific), Structure (logical format), and Sensitivity (fair and unbiased).
A. Yes, prompt engineering is a skill and in vogue. It requires thorough thinking in crafting effective prompts that guide LLMs towards desired outcomes.
A. Prompt engineers are skilled professionals in understanding the input (prompts) and excel in creating reliable and robust prompts, especially for large language models, to optimize their performance and ensure they generate highly accurate and creative outputs.
![]()
I’m Bharat Kumar, a content editor at The Next Tech with 3+ years of experience in writing and editing technology content. Currently, exploring Generative AI (GenAI) through Analytics Vidhya and sharing my learnings by writing engaging, story-driven articles on Artificial Intelligence, Generative Engines, and Machine Learning.
Login to continue reading and enjoy expert-curated content.




