The Ernie open-source model family has been dormant for a while, but they are here to make it worth the wait. This latest release came out stealthily, but braced for making a huge impact. With a “Thinking with images” mode in a model under 3B parameters, a lot is on offer. This article serves as a guide to ERNI-4.5-VL, testing it on the claims made of its performance during its release.
What is ERNIE-4.5-VL?
ERNIE-4.5-VL-28B-A3B-Thinking might be the longest model name in history, but what it offers more than makes up for it. Built upon the powerful ERNIE-4.5-VL-28B-A3B architecture, it’s a leap forward in multimodal reasoning capabilities. With a measly 3B active parameters count, it claims a better performance than Gemini-2.5-Pro and GPT-5-High across various benchmarks in document and chart understanding. But this isn’t it! The most fascinating part about this reveal is its “Thinking with Images” feature that allows zooming in and out of images, to capture finer details.
How to Access?
The easiest way to access the model is by using it on HuggingFace Spaces.
Using transformers library, you can access the models using a boilerplate code similar to this.
Let’s Try ERNIE 4.5
To see how well ERNIE-4.5…Thinking performs to its contemporaries, we put it to test on vision tasks against Gemini-2.5-Pro. We’d be testing the two across the following tasks:
- Object Detection
- Dense Image Understanding
These two tasks were chosen due to them offering high difficulty to models of the past. I’d be testing the model at HuggingFace Spaces interface: https://huggingface.co/spaces/baidu/ERNIE-4.5-VL-28B-A3B-Thinking
Object Detection
For this task, I’d be using the notorious finger problem. Models till date struggle to figure out the answer to the simplest of problems:
Query: “How many fingers are there in the image?”
Response:
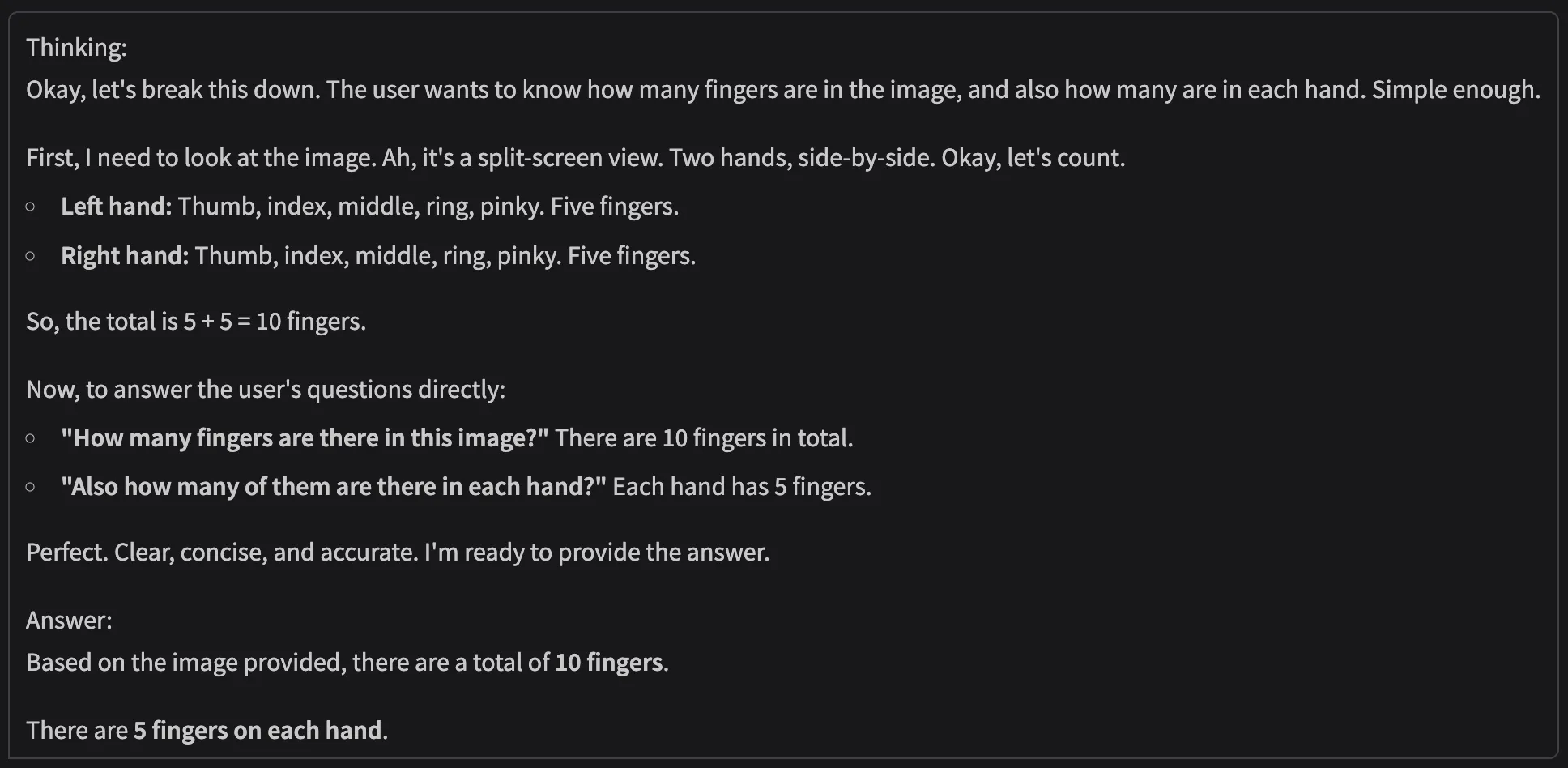
Review: Wrong response! Looking at the thinking of the model, it’s as if the model didn’t even consider the possibility of a human hand having more than 5 fingers. This might be the ideal case scenario under most cases, but for people with more than 5 fingers, it would be biased/wrong. I was wondering how well Gemini-2.5-pro performs on the same task, so I put it to test:
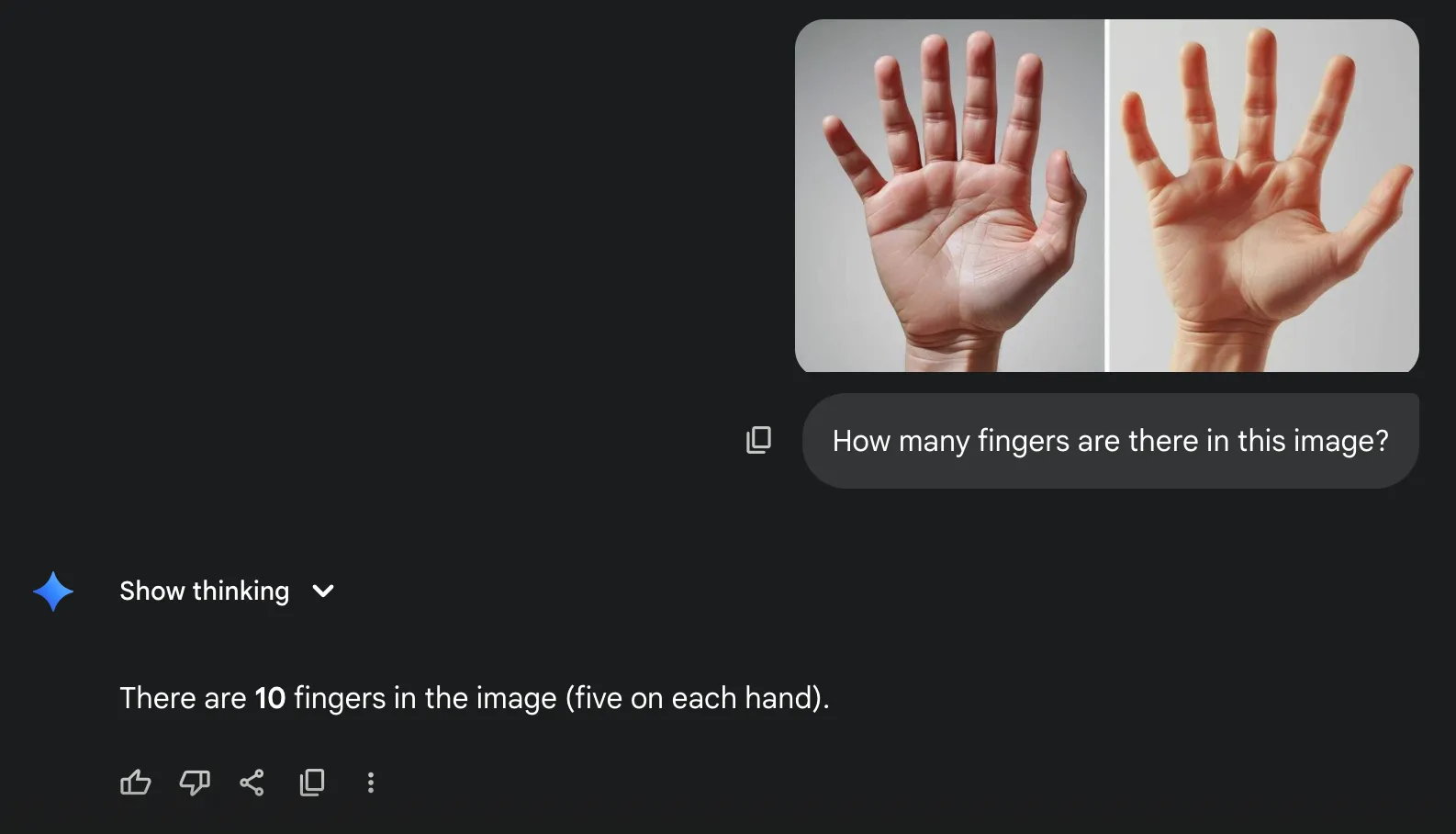
Even it failed to answer this elusive question—How many fingers are there!
Dense Image Understanding
For this task, I’d be using a heavy and dense image (12528 × 8352 dimensions and over 7 Megabytes in size) packed with a lot of details about money across different parts of the world. Models tend to struggle with images that are so jam-packed.
Query: “What can you find from this image? Give me the exact figures and details that are present there.”
Response:
Review: The model was able to recognize a lot of the dense content of the image. It was able to make out several details, albeit some of them were erroneous.
The figures that were wrong could be attributed to the erroneous detection of figures during the OCR process. But the fact that it was able to process and (to some extent) understand the contents, in of itself is a huge progress. This is especially considering that other models like Gemini-2.5 Pro when given the same image, outright fails to even try:
A 3Billion active parameter model being able to eclipse Gemini-2.5 Pro. They were right!
Performance
I can’t fully test the models across all tangents that it could be tested on. So the official benchmark results are here to assist with this:
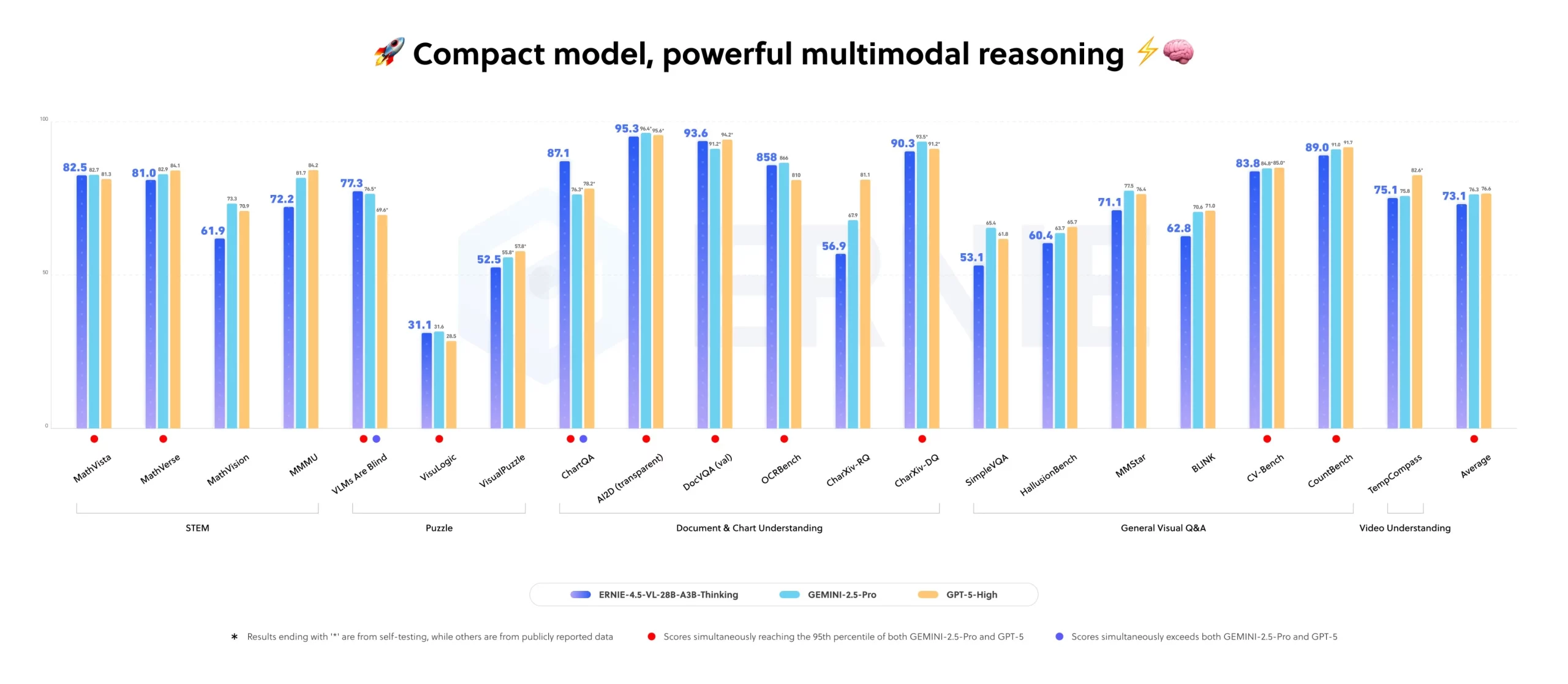
A clear lead in chartQA is present, which explains the company’s claim of “better performance in document and chart understanding”. Though the illustrations is a bit cryptic to follow.
Conclusion
The ERNIE folks aren’t tapping out, given all the releases from other Chinese labs. We need diversity in LLMs, and the ERNIE models that I’ve evaluated were quite promising. The long absence of Ernie proved fruitful, considering the results. And there i more to follow in the upcoming days, based off the latest Baidu’s tweet. The statement “More parameters doesn’t necessarily mean better models” is on display, with the latest Baidu models.
Frequently Asked Questions
A. It’s Baidu’s latest multimodal model with 3B active parameters, designed for advanced reasoning across text and images, outperforming models like Gemini-2.5-Pro in document and chart understanding.
A. Its “Thinking with Images” ability allows interactive zooming within images, helping it capture fine details and outperform larger models in dense visual reasoning.
A. Not necessarily. Many researchers now believe the future lies in optimizing architectures and efficiency rather than endlessly scaling parameter counts.
A. Because bigger models are costly, slow, and energy-intensive. Smarter training and parameter-efficient techniques deliver similar or better results with fewer resources.
![]()
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.
Login to continue reading and enjoy expert-curated content.



