Everyone talks about big AI models like ChatGPT, Gemini, and Grok. What many people do not realize is that most of these models use the same core architecture called the Transformer. Recently, another term has started trending in the generative AI space called Mixture of Experts or MoE. This has created a lot of confusion around transformer vs MoE. Some people think MoE is a completely new architecture. Others believe it is just a larger Transformer. This makes it hard to understand what is actually happening behind the scenes.
Is MoE a replacement for Transformers, or is it simply a smarter way to scale them? Are the two really different? These questions come up often when people hear about Transformers and MoE.
In this article, I will explain everything in simple terms. You will learn what Transformers are, what MoE adds, how they differ, and when you would choose one over the other.
Let’s dive in.
Understanding Transformers
Before we compare Transformers and MoE, we need to understand what a Transformer actually is.
At a high level, a Transformer is a neural network architecture designed to handle sequences like text, code, or audio. It does this without processing tokens one by one like RNNs or LSTMs. Instead of reading left to right and carrying a hidden state, it looks at the entire sequence at once. It then decides which tokens matter most to each other. This decision process is called self-attention.
I know this can sound confusing, so here is a simple way to think about it. Imagine a Transformer as a black box. You give it an input and it gives you an output. For example, think of a machine translation tool. You type a sentence in one language and it produces the translated sentence in another language.

Components of Transformers
Now how is the Transformer converting one sentence into another?
There are two important components: an encoding component and a decoding component, both responsible for the conversion. The encoding component is a stack of encoders, and the decoding component is a stack of decoders of the same number.
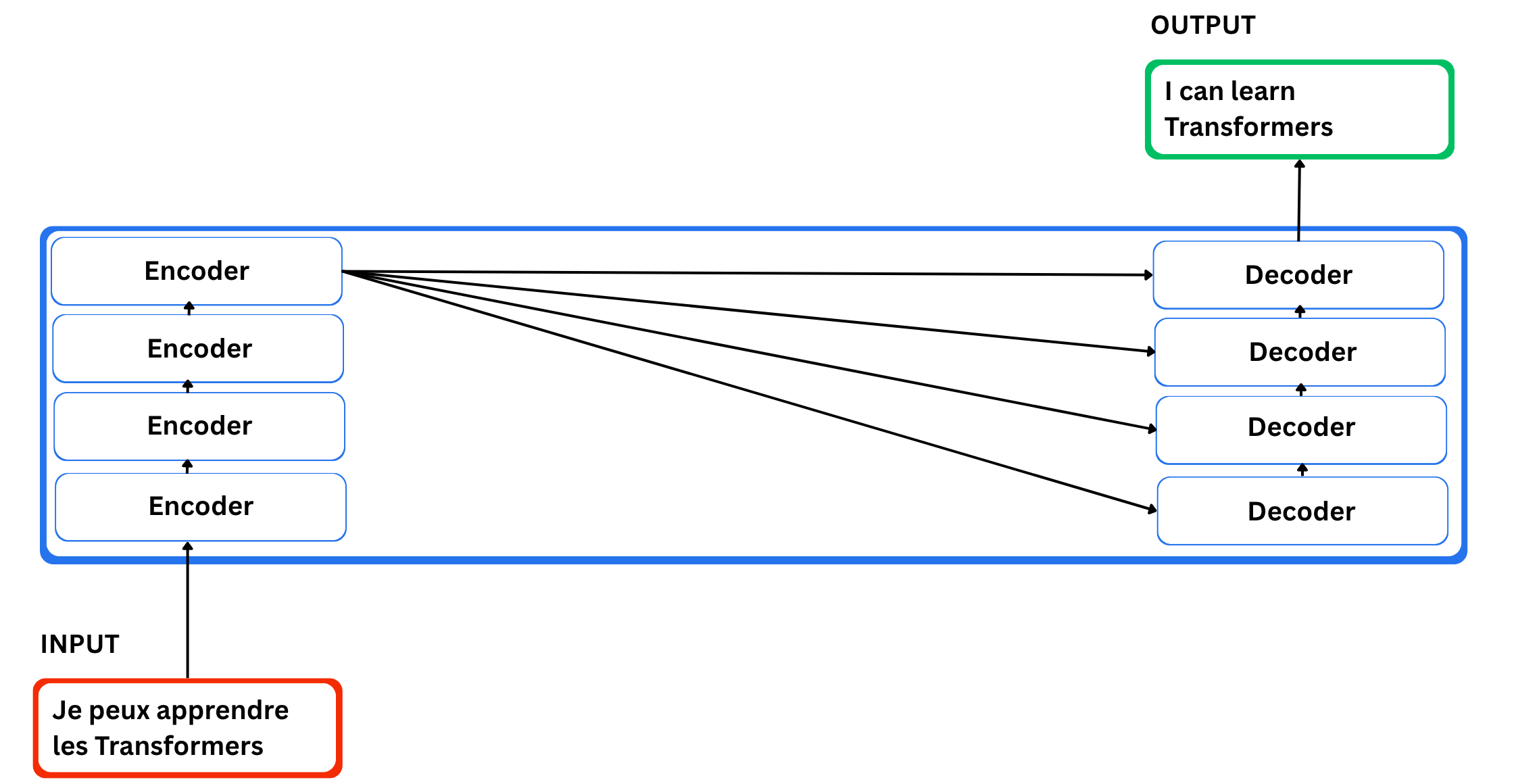
The Role of Encoders
These encoders are all similar in structure, and each of them is divided into two sublayers: a feed-forward neural network and a self-attention layer. In the encoder, the input tokens first go through the self-attention layer. This layer allows the model to look at all the other words in the sentence while it processes a given word, so it can understand that word in context. The result of self-attention is then passed into a feed-forward network, which is a small MLP. The same network is applied to every position in the sequence.
The Role of the Decoder
The decoder uses these two parts as well, but it has an extra attention layer in between. That extra layer lets the decoder focus on the most relevant parts of the encoder output, similar to how attention worked in classic seq2seq models.
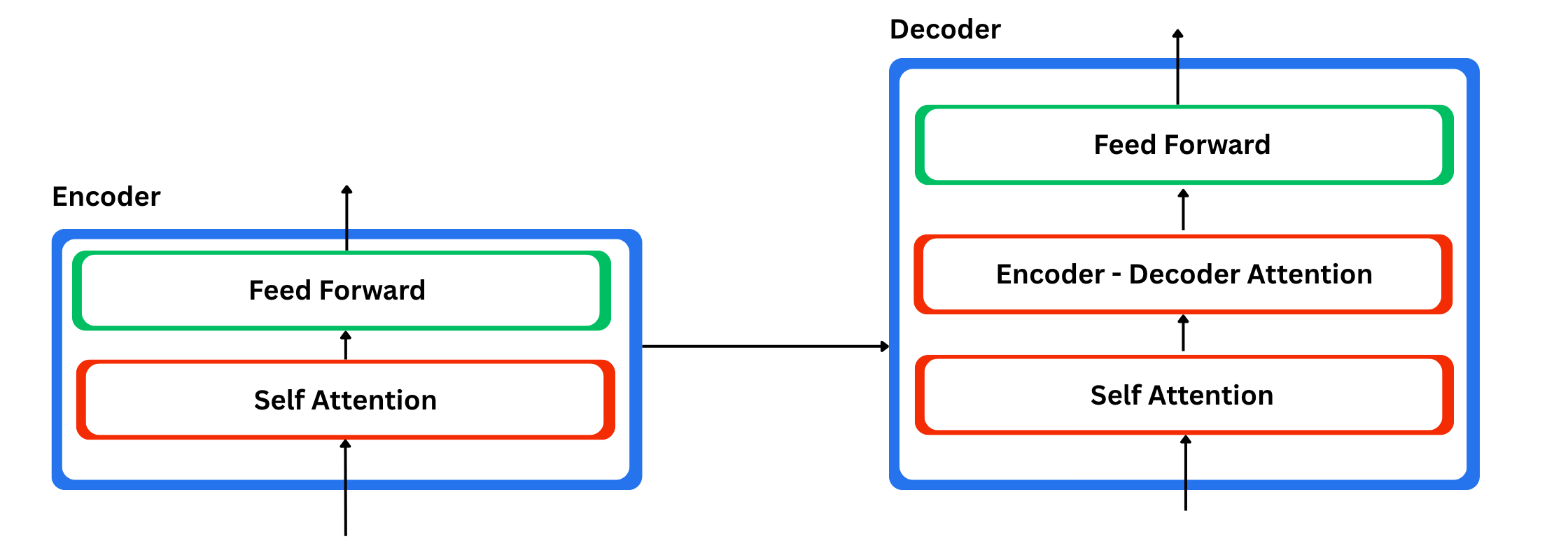
If you want a detailed understanding of Transformers, you can check out this amazing article by Jay Alammar. He explains everything about Transformers and self-attention in a clear and comprehensive way. He covers everything from basic to advanced concepts.
When and where to use Transformers?
Transformers work best when you need to capture relationships across a sequence and you have enough data or a strong pretrained model.
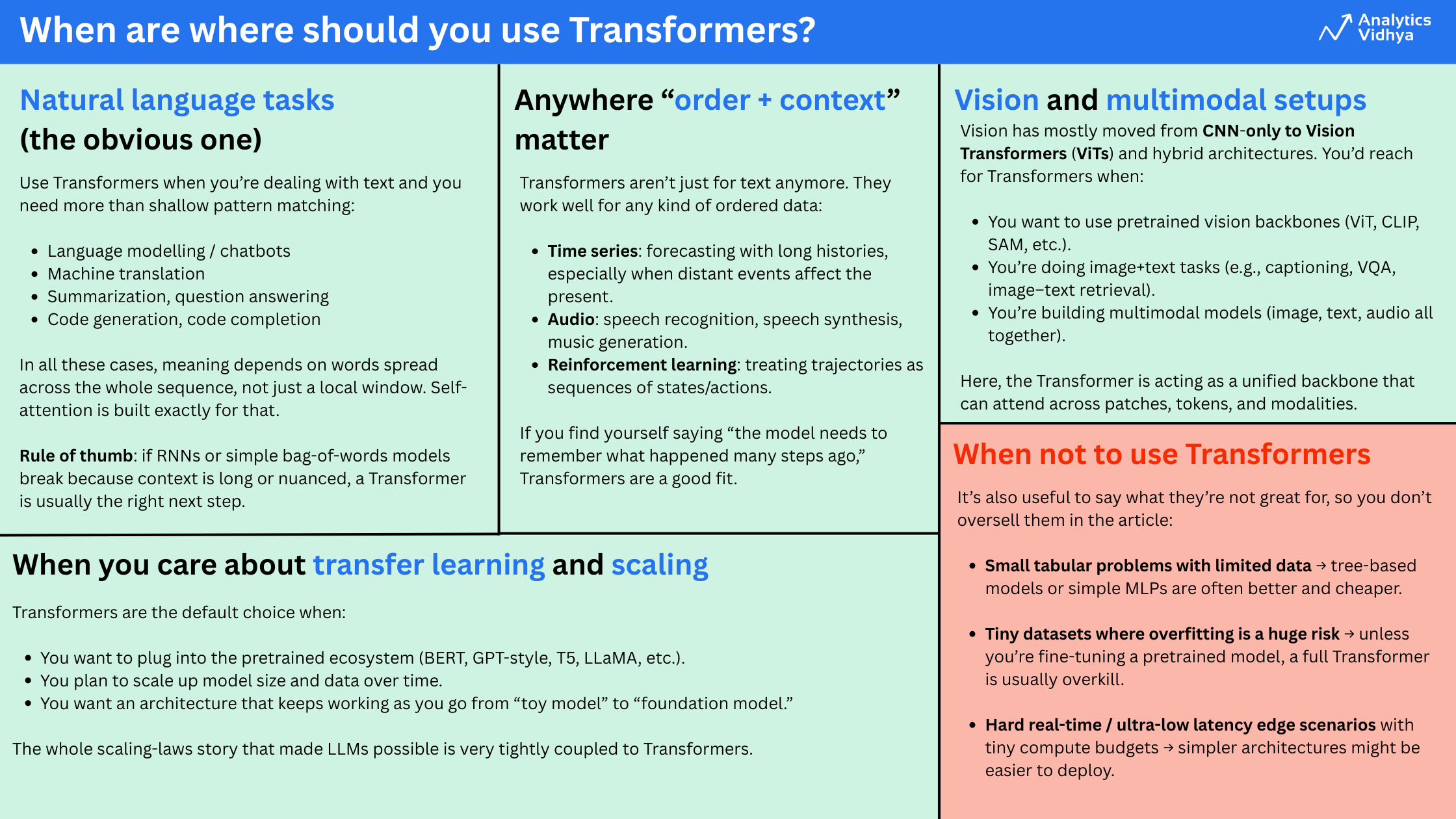
Use Transformers when your data has order and context, and when the relationships between different parts of the sequence matter over long ranges. They work extremely well for text tasks like chatbots, translation, summarization, and code. They are also effective for time series, audio, and even vision and multimodal problems that combine text, images, or audio.
In practice, Transformers perform best when you can start from a pretrained model or when you have enough data and compute to train something meaningful. For very small tabular datasets, tiny problems, or situations with strict latency limits, simpler models are usually a better fit. But once you move into rich sequential or structured data, Transformers are almost always the default choice.
Understanding Mixture of Experts(MoE)
Mixture of Experts is popular architecture that use multiple experts to improve the existing transformer model or you can say to improve the quality of the LLMs. There are majorly two component that define a MoE:
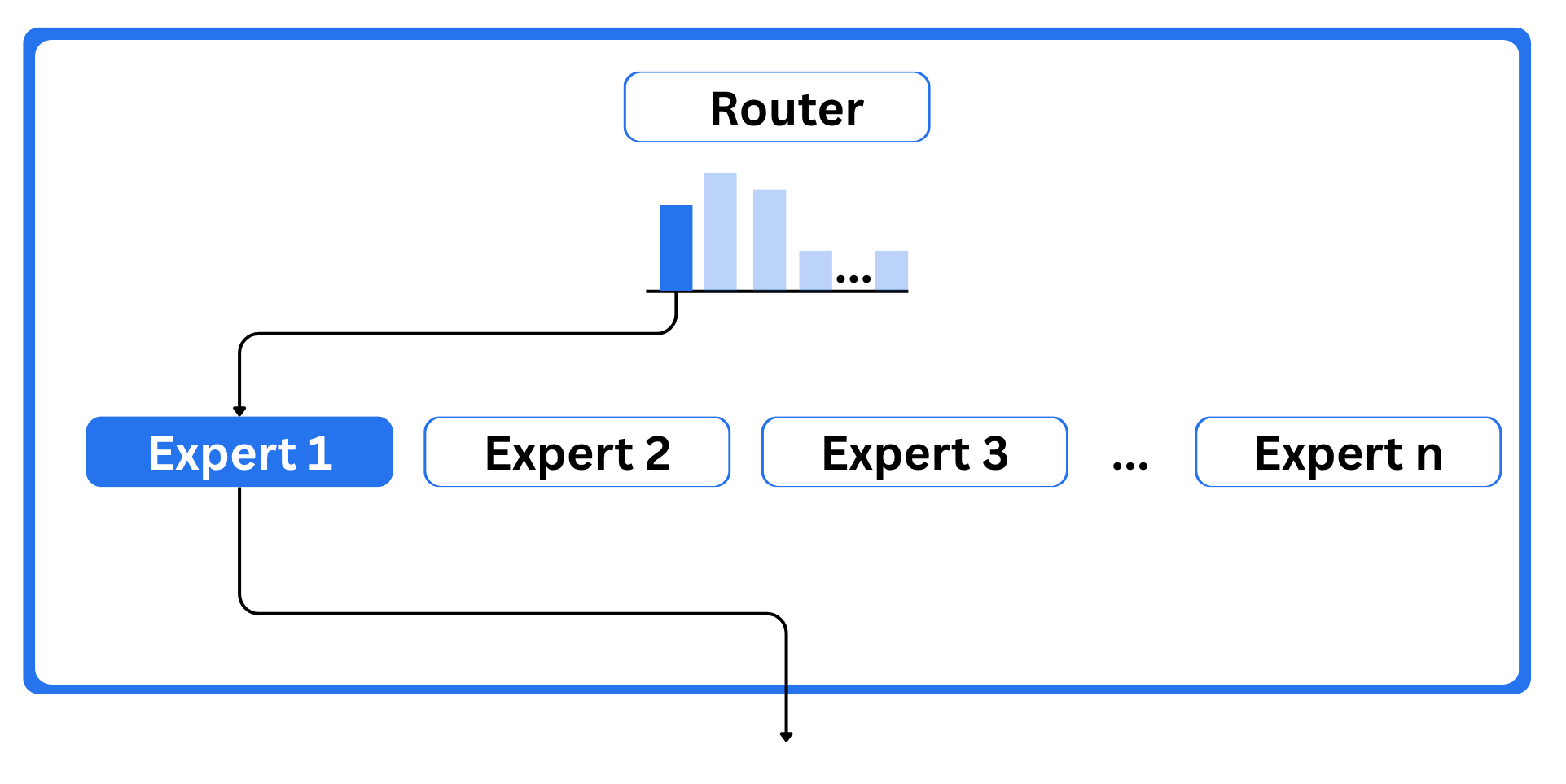
- Experts: Each feed-forward neural network layer is replaced by a group of experts, and only a subset of them is used for any given token. These experts are typically separate FFNNs.
- Router or gate network: This decides which tokens are sent to which experts. It acts like a watch guard.
To keep this article short and focused on Transformers and MoE, I am only covering the core ideas rather than every detail. If you want a deeper dive, you can check out this blog by Marteen.
When and where to use Mixture of Experts?
Let’s break it down into the two things you are really asking:
- When is MoE actually worth it?
- Where in a model does it make sense to plug it in?
You should use MoE when:

Where in a model / pipeline should you use MoE?
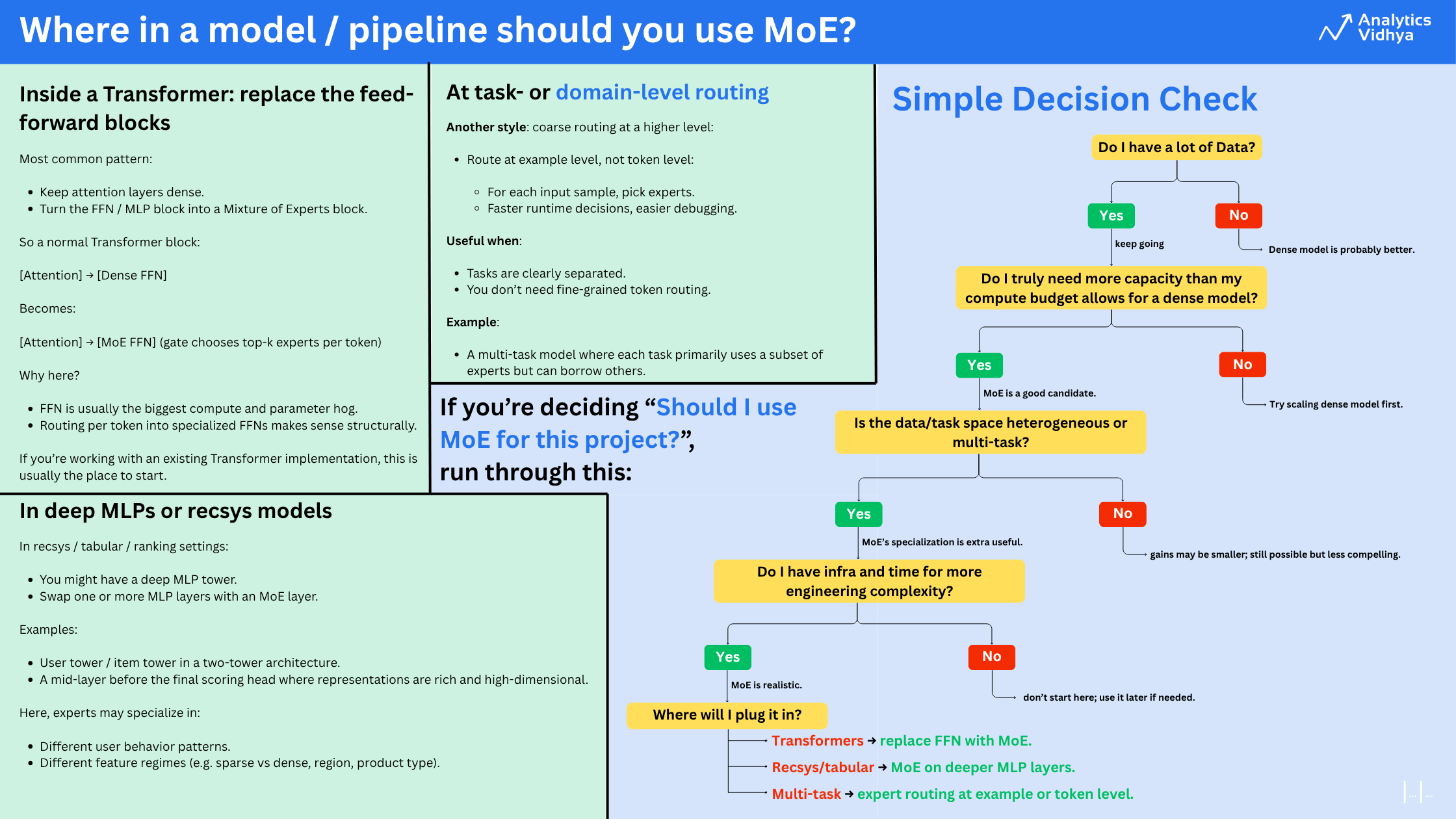
Difference between Transformers and MoE
They mainly differ in the decoder block.
A Transformer uses a single feed-forward network, while MoE uses multiple experts, which are smaller FFNNs compared to those in Transformers. During inference, only a subset of these experts is selected. This makes inference faster in MoE.
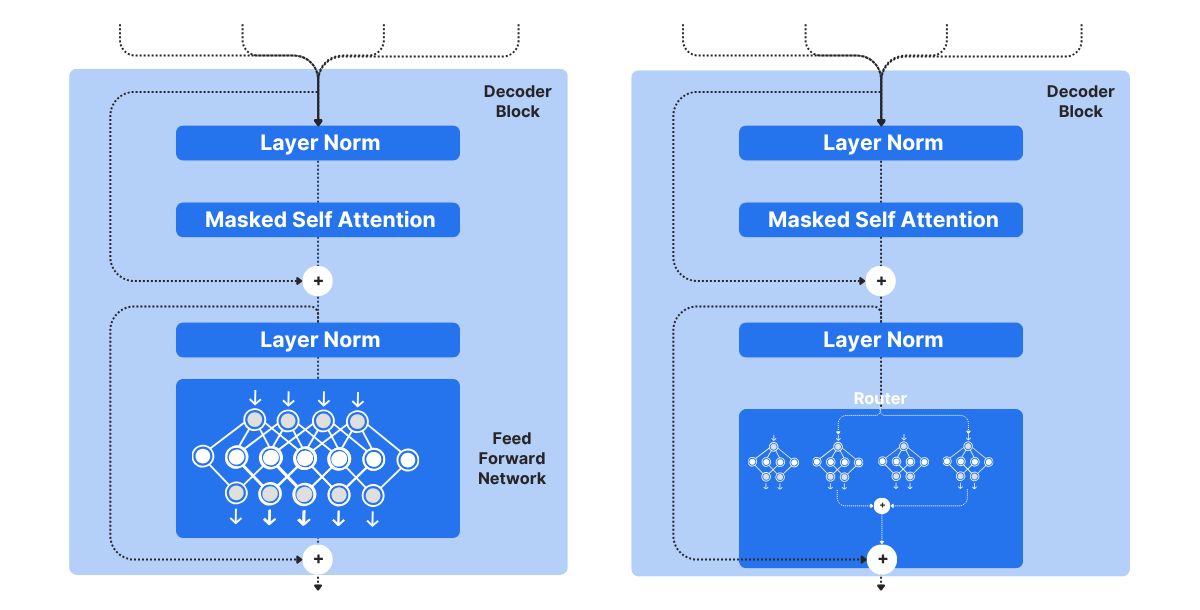
The network in MoE contains multiple decoder layers:
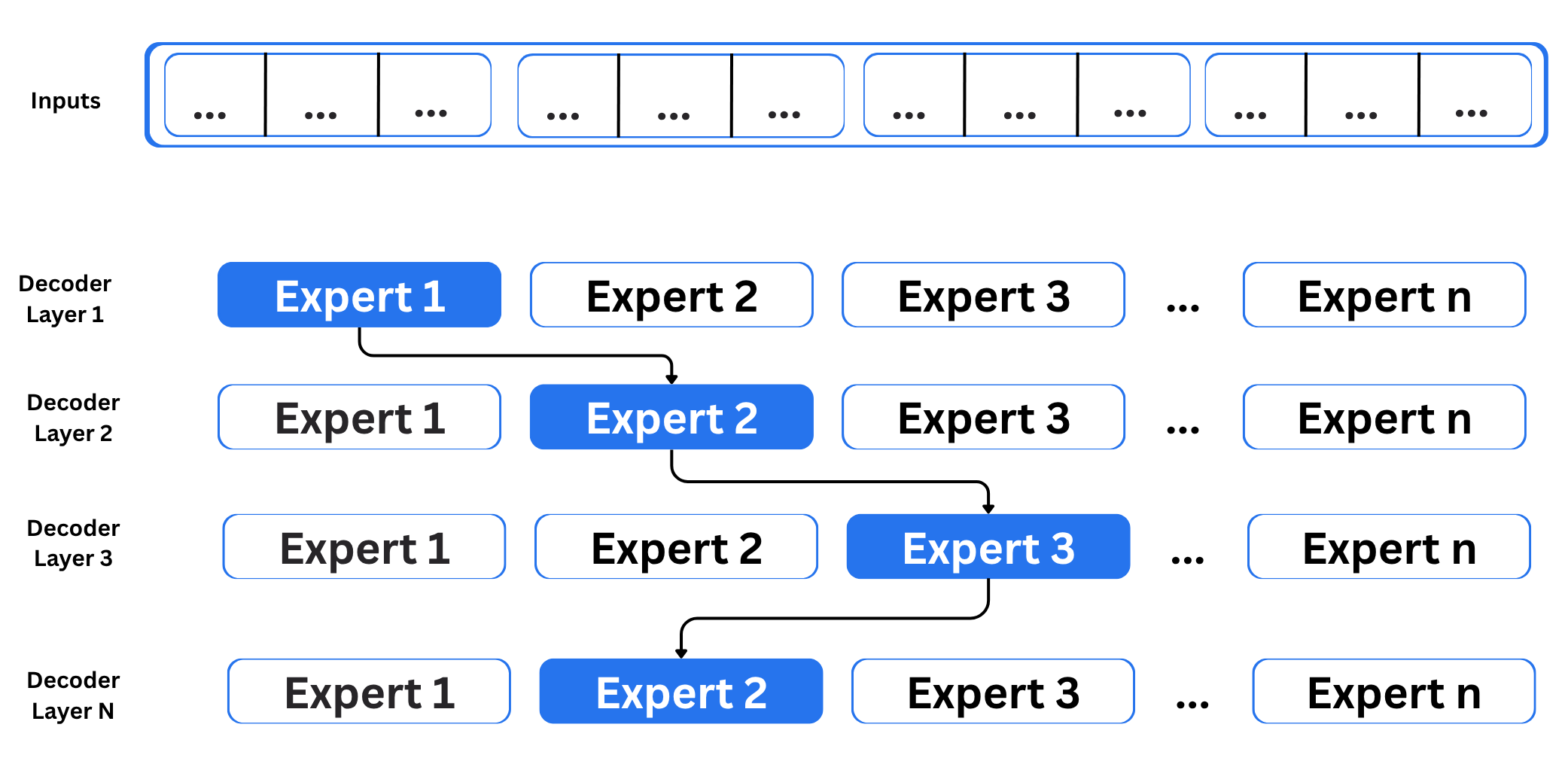
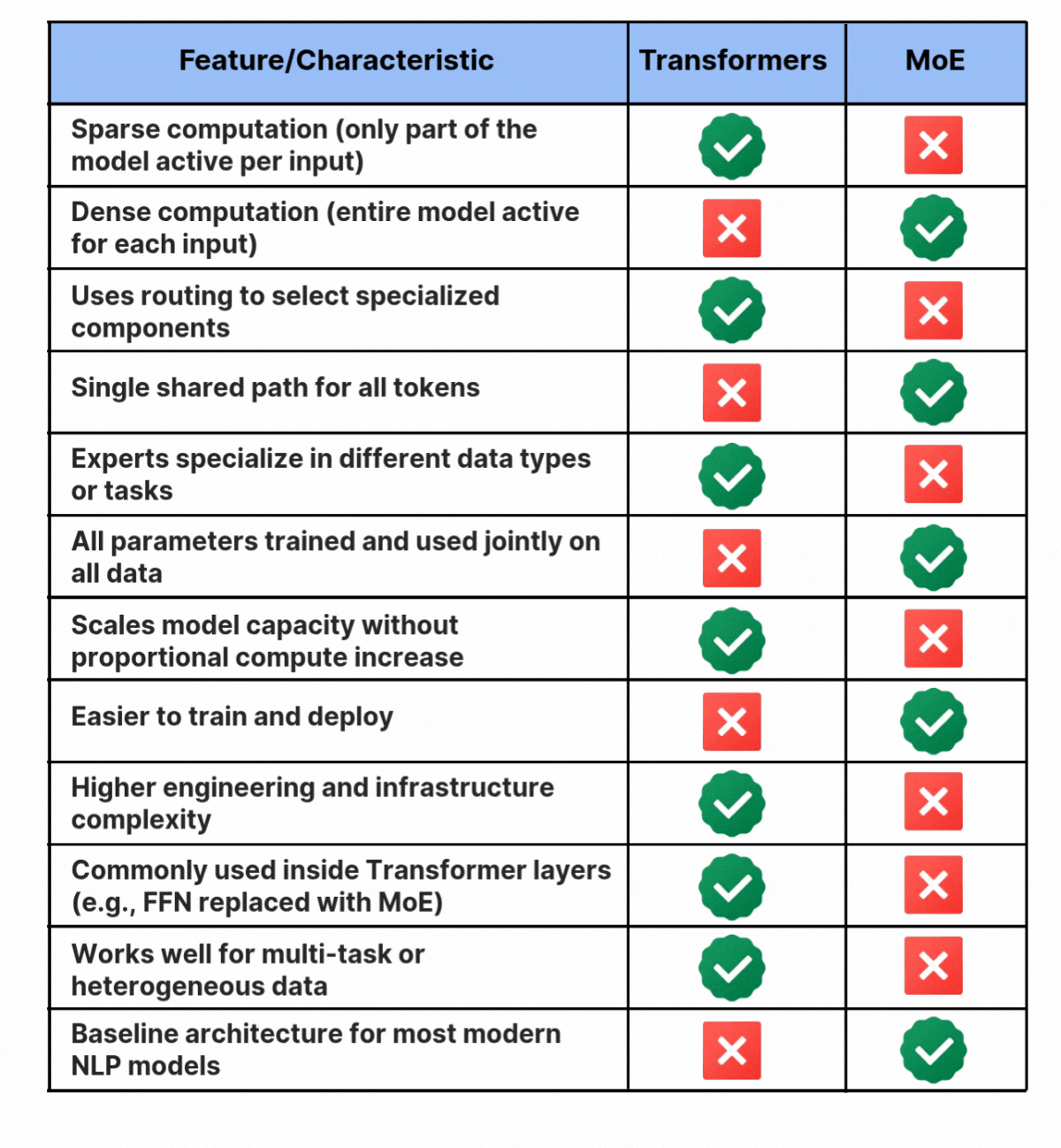
Since the network includes multiple decoder layers, the text is processed by different experts at each layer, and even within a single layer the selected experts can change from token to token. The question is how the model decides which experts to use. This is handled by the router. The router works like a multi-class classifier that produces softmax scores for all experts. The model then selects the top K experts based on these scores. The router is trained jointly with the rest of the network and learns over time which experts are best suited for each input. You can refer to the table below for more information about the differences between the two.
Conclusion
Both Mixture of Experts and Transformers aim to scale model intelligence, but they do it in different ways. Transformers use dense computation, where every parameter contributes to every prediction. This makes them simple, powerful, and straightforward to deploy. MoE uses conditional computation, activating only a subset of parameters for each input. This gives the model larger capacity without increasing compute in the same proportion and allows different experts to specialize.
In simple terms, Transformers define how information flows through a model, and MoE decides which parts of the model should handle each input. As models grow and tasks become more complex, the most effective systems will likely combine both approaches.
Frequently Asked Questions
A. ChatGPT is built on the Transformer architecture, but it is not just a Transformer. It includes large-scale training, alignment techniques, safety layers, and sometimes MoE components. The foundation is the Transformer, but the full system is much more advanced.
A. GPT uses the Transformer decoder architecture as its core building block. It relies on self-attention to understand relationships across text and generate coherent output. Since its entire design is based on Transformer principles, it is classified as a Transformer model.
A. Transformers are generally grouped into encoder-only models, decoder-only models, and encoder–decoder models. Encoder-only models work best for understanding tasks, decoder-only models for generation tasks, and encoder–decoder models for structured input-to-output tasks like translation or summarization.
A. Transformers use dense computation where every parameter helps with every prediction. MoE uses conditional computation and activates only a few experts for each input. This allows much larger capacity without proportional compute cost. Transformers handle flow, while MoE handles specialization.
![]()
Growth Hacker | Generative AI | LLMs | RAGs | FineTuning | 62K+ Followers https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/
Login to continue reading and enjoy expert-curated content.




