It seems like every other week, there’s a new AI model making waves, and the pace is only picking up. The latest to catch my eye, and many others in the AI community, is Qwen3-Next. It didn’t arrive with a splashy campaign, but rather a quiet, yet impactful, presence on Hugging Face. With a measly 80 billion parameters and a 32K token context window, it delivers more than 10x higher throughput — achieving extreme efficiency in both training and inference. It feels like a genuine leap forward for open-source AI.
But what exactly is Qwen3-Next, and why is it generating so much buzz? And more importantly, how does it stack up against the titans we’ve grown accustomed to? Let’s dive in and explore what makes this model so special.
What is Qwen3-Next?
At its core, Qwen3-Next-80B-A3B is Alibaba’s newest large language model, designed to push the boundaries of performance, efficiency, and context understanding. Built on hybrid models + linear attention for super long context handling, it boasts 80 billion total parameters. But its real genius lies in its selective power. Instead of activating all those parameters for every task, it intelligently uses only about 3 billion at a time. This gives it the 80B (max parameters) and A3B, which is the minimum parameters, in its model name. Think of it like having a massive library of specialists, where only the most relevant experts are called upon for a given problem.
This incredible efficiency is the foundation upon which specialized versions are built. The Qwen3-Next-Instruct model is tuned for general-purpose instruction-following, creative generation, and everyday tasks, while the Qwen3-Next-Thinking model is fine-tuned to tackle complex, multi-step reasoning challenges. So, you don’t just get a faster, more cost-effective operation; you get a framework that assembles different teams of experts for distinct missions, whether it’s following instructions smoothly or diving into deep, analytical thought.
Key Features of Qwen3-Next
Key Features of Qwen3-Next include:
- Hybrid Attention (3:1 mix): 75% Gated DeltaNet (linear attention) for efficiency + 25% Gated Attention for recall. Optimized with gated head dimensions and partial rotary embeddings.
- Ultra-Sparse MoE: 80B total params, only ~3B active per step. 512 experts, 10+1 activated per inference. Global load-balancing keeps training stable and efficient.
- Training Stability: Output gating prevents attention sinks; Zero-Centered RMSNorm improves norm control; weight decay and fair router initialization reduce instability.
- Multi-Token Prediction (MTP): Improves speculative decoding acceptance, aligns training with inference, and boosts throughput without sacrificing accuracy.
- Efficiency Gains: Uses <80% GPU hours of Qwen3-30B and just ~9.3% of Qwen3-32B’s compute, yet outperforms both. Prefill throughput: 7–10x faster, decode throughput: 4–10x faster.
- Base Model Strength: Despite activating only 1/10th of Qwen3-32B’s parameters, it matches or beats it across most benchmarks.
- Instruct Model: Strong in instruction-following and ultra-long context tasks; rivals Qwen3-235B for lengths up to 256K tokens.
- Thinking Model: Excels in reasoning, chain-of-thought, and analytical tasks; comes close to Qwen3-235B-Thinking while being much cheaper to run.
How to access Qwen3-Next?
Alibaba has made Qwen3-Next remarkably accessible. The following are some of the ways of accessing it:
- Official Web App: The easiest way to try it is at Qwen’s web interface at chat.qwen.ai.
- API Access: Developers can access Qwen3-Next via its official API. It’s designed to be OpenAI-compatible, so if you’ve used OpenAI’s tools before, integration should feel familiar. Both the Instruct and Thinking models API can be accessed here.
- Hugging Face: For those who want to run it locally or fine-tune it, the raw weights are available under an open license. This is where the true power of open-source comes into play, allowing for customization and deeper exploration. Qwen3-Next can be accessed here.
Hands-On: Testing the Mettle
Enough words; time for some action! Here, I’d be testing the capabilities of Qwen-Next across several tasks:
- Agentic Capabilities
- Coding Capabilities
- Multimodal Capabilities
1. Agentic Capabilities
Prompt: “I read a research paper about K2 Think, a new LLM. Find the relevant research paper and then write a blog explaining the main components of the research paper. Finally, create a LinkedIn post and an Instagram post talking about the same”
Response:
-

Blog Component -

LinkedIn Post
2. Coding Capabilities
Prompt: “Create a website that is a combination of Reddit and Instagram.”
Response:
You can see the created website yourself via this deployed link.
3. Multimodal Capabilities
Prompt: “Go through the contents of this video SRT and in 5 lines explain to me what is happening in the video. Finally, write a prompt to generate a suitable cover image for this video.”
The input file can be found here.
Response:
Image Generated:

Verdict
My experience with the latest Qwen3-Next model has been largely positive. While it might seem a bit slow based on Qwen’s own benchmarks, in practice, it feels quicker than most reasoning models. It understands tasks well, follows instructions closely, and delivers strong results with efficiency. The only drawback is that it doesn’t yet auto-trigger its built-in tools—for example, testing generated code requires manually enabling the artifact tool, and document-based image generation needs the image tool selected separately. That said, QwenChat offers nearly every tool you could want, and combined with Qwen3-Next’s more natural responses compared to its counterparts, it’s a model I see myself spending much more time with.
Qwen3-Next: Benchmarks and Performance
You’d think: 80b parameters only! That’s like a quarter of the state-of-the-art model’s parameters. Surely, it shows up in its performance, right?
This is where Qwen3-Next turns the tables. Instead of offering a downsampled version of the latest models that are available out there, it goes shoulder-to-shoulder with them in terms of their performance. And the benchmarks hit this point home.
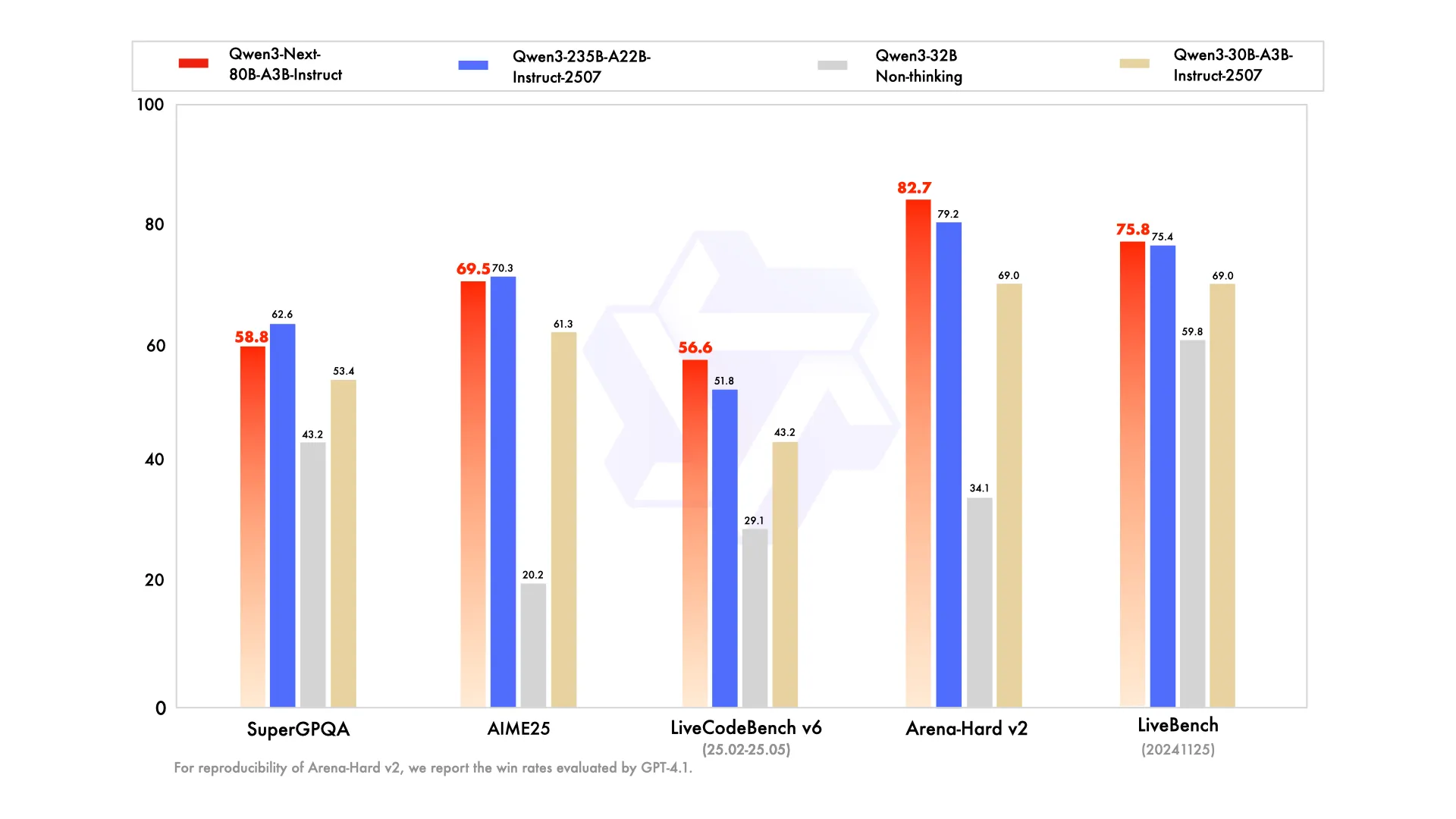
The performance of this optimized model is comparable to Qwen’s previous flagship models. More notably, on certain complex reasoning benchmarks, it has even been observed to surpass Google’s Gemini-2.5-Flash-Thinking. This is a significant achievement, particularly given its focus on efficiency and long-context processing, suggesting that “smarter” can indeed be “leaner.”
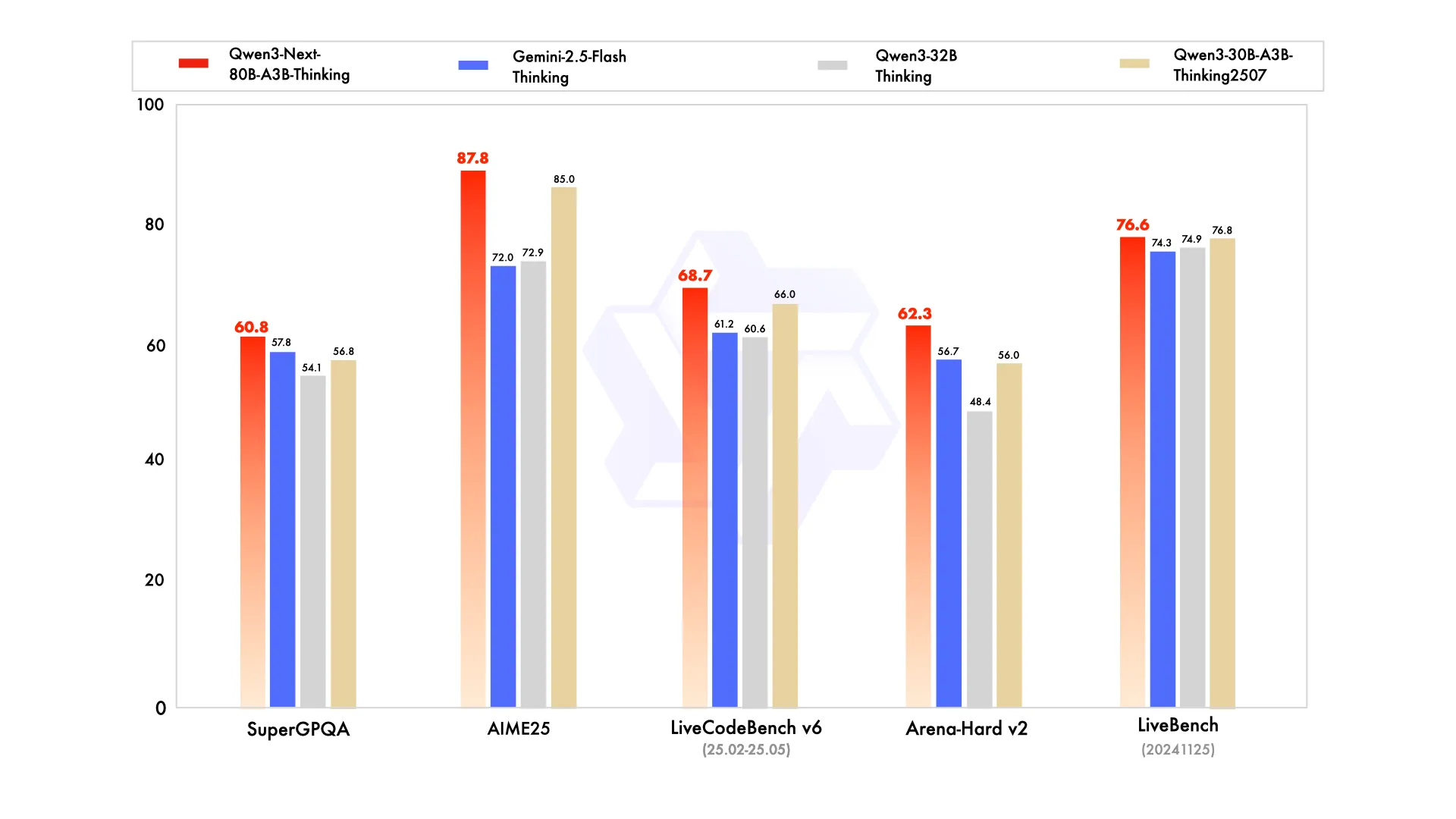
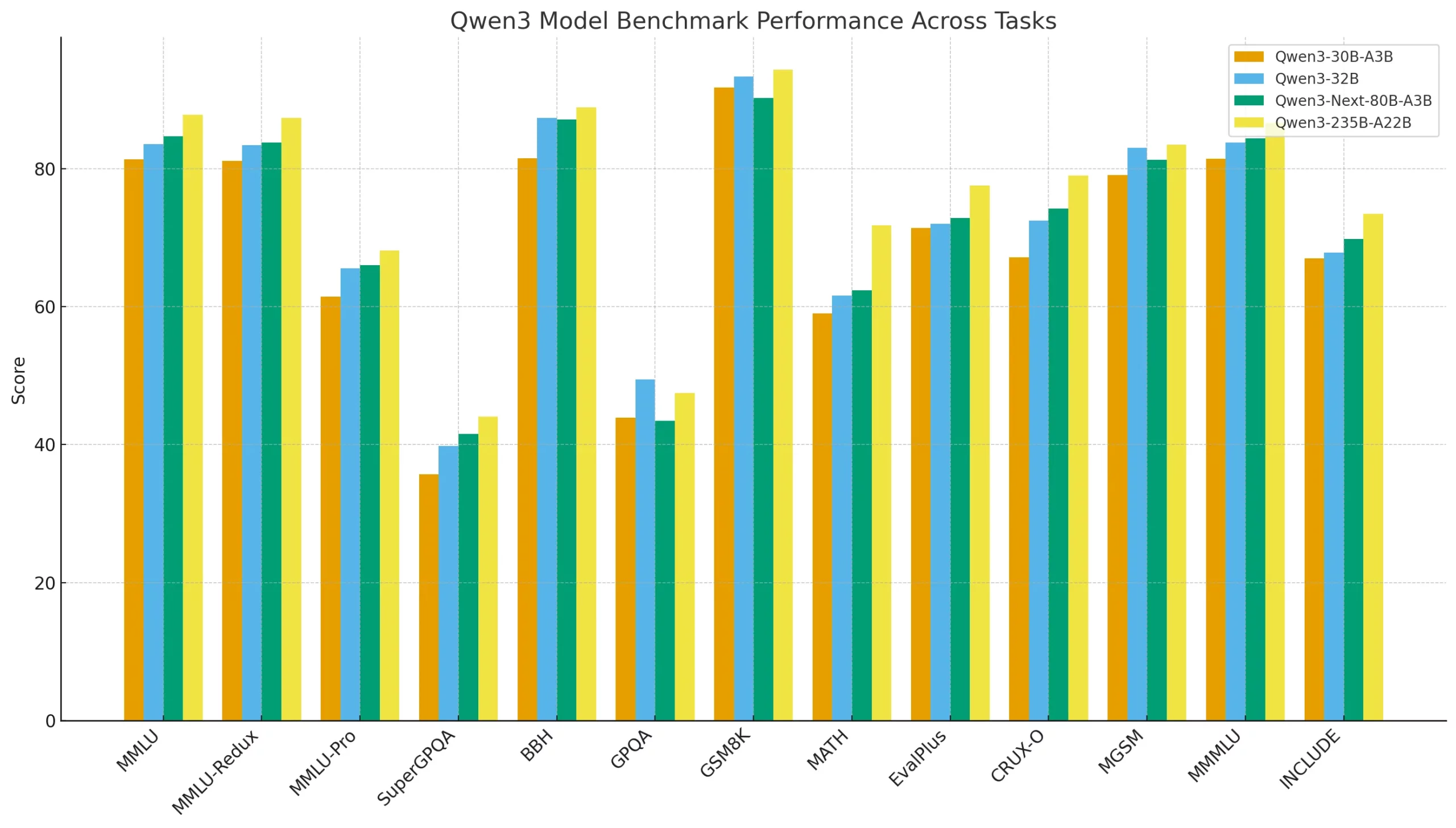
But what about the performance across industry benchmarks? There too, Qwen-Next produces favorable results. The table below compares the performance of different Qwen3 models across a variety of benchmarks. It shows how the newer Qwen3-Next-80B-A3B stacks up against smaller models like Qwen3-30B-A3B, a dense baseline (Qwen3-32B), and the massive Qwen3-235B-A22B. The metrics span general reasoning (MMLU, BBH), math and coding tasks (GSM8K, MATH, EvalPlus), and multilingual evaluations. It highlights not just raw capability, but also the trade-offs between dense and sparse Mixture-of-Experts (MoE) architectures.
The Road Ahead
Qwen3-Next isn’t just another large model; it’s a blueprint for a more sustainable and accessible AI future. By masterfully blending different architectural techniques, the Qwen team has shown that we can achieve top-tier performance without the brute-force approach of simply scaling up dense models.
This provides a promising outlook for those who don’t house entire workstations for training their models. With a clear emphasis on optimization, the days of endlessly scaling hardware to up the ante are gone.
For developers and businesses, this means more power at a lower cost, faster inference for better user experiences, and the freedom to innovate that only open-source can provide. This is more than just a good model; it’s the start of a new and exciting journey.
Frequently Asked Questions
A. Alibaba’s latest large language model uses a Sparse Mixture-of-Experts design. It has 80B parameters but only activates ~3B per task, making it efficient and cost-effective.
A. It uses a hybrid attention mechanism that can natively process up to 256,000 tokens, enabling it to work with entire books or large documents.
A. You can access it via Qwen’s web app (chat.qwen.ai), through their API, or download the raw weights from Hugging Face.
A. There’s an Instruct version for general tasks and a Thinking version tuned for reasoning and analytical applications.
A. Benchmarks show it competes with Alibaba’s previous flagships and even surpasses Google’s Gemini-2.5-Flash-Thinking on certain reasoning benchmarks.
![]()
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.
Login to continue reading and enjoy expert-curated content.




