As AI gets smarter, agents now handle complex tasks. People make decisions across whole workflows with plenty of efficiency and good intent, but never with perfect accuracy. It’s easy to drift off-task, over-explain, under-explain, misread a prompt, or create headaches for whatever comes next. Sometimes the result ends up off-topic, incomplete, or even unsafe. And as these agents begin to take on actual work, we need a mechanism for checking their output before letting it go forward. This is just another reason why CrewAI has branched out into using task guardrails. Guardrails create the same expectations for every task: length, tone, quality, format, and accuracy are clarified by rules. If the agent drifts from the guardrail, it will gently correct course and force the agent to try again. It holds steady the workflow. Guardrails will help agents stay on track, consistent, and reliable from start to finish.
What Are Task Guardrails?
Task guardrails are validation checks applied to a particular task, in CrewAI. Task guardrails are run immediately following an AI agent completing a task-related output. Once the AI generates its output, if it conforms to your rules, we will continue to take the next action in your workflow. If not, we will stop execution or retry according to your configurations.
Think of a guardrail as a filter. The agent completes its work, but before that work has an impact on other tasks, the guardrail reviews the agent’s work. Does it follow the expected format? Does it include the required keywords? Is it long enough? Is it relevant? Does it meet safety criteria? Only when the work has checked against these parameters will the workflow continue.
Read more: Guardrails in LLM
CrewAI has two types of guardrails to assist you to ensure compliance with your workflows:
1. Function-Based Guardrails
This is the most frequently used approach. You simply write a function in Python that checks the output from the agent. The function will return:
- True if output is valid
- False with optional feedback if output is not valid
Function-based guardrails are best suited to rule-based scenarios such as:
- Word count
- Required phrases
- JSON formatting
- Format validation
- Checking for keywords
For example you might say: “Output must include the phrases electric kettle and be at least 150 words long.”
2. LLM-Based Guardrails
These guardrails utilized an LLM in order to assess if an agent output satisfied some less stringent criteria, such as:
- Tone
- Style
- Creativity
- Subjective quality
- Professionalism
Instead of writing code, just provide a text description that might read: “Ensure the writing is friendly, does not use slang, and feels appropriate for a general audience.” Then, the model would examine the output and decide whether or not it passes.
Both of these types are powerful. You can even combine them to have layered validation.
Why Use Task Guardrails?
Guardrails exist in AI workflows for various important reasons. Here’s how they are typically used:
1. Quality Control
AI produced outputs may vary in quality, as one prompt may create an excellent response, while the next misses the goal entirely. Guardrails help to govern the quality of the output because guardrails create the expectation of minimum output standards. If an output is too short, unrelated to the request, or poorly organized, the guardrail ensures action will be taken.
2. Safety and Compliance
Some workflows require strict accuracy. This rule of thumb is especially true when working in healthcare, finance, legal, or enterprise use-cases. Guardrails are used to prevent hallucinations and unsafe compliance outputs that violate guidelines. CrewAI has a built in ‘hallucination guardrail’ that seeks out fact based content to enhance safety.
3. Reliability and Predictability
In multi-step workflows, one bad output may cause everything down stream to break. A badly formed output to a query may cause another agent’s query to crash. Guardrails protect from invalid outputs establishing reliable and predictable pipelines.
4. Automated Retry Logic
If you do not want to deal with manually fixing outputs, you may have CrewAI retry automatically. If the guardrail fails, allow CrewAI to retry outputing the information up to two more times. This feature creates resilient workflows and reduces the amount of supervision required during a workflow.
How Task Guardrails Work?
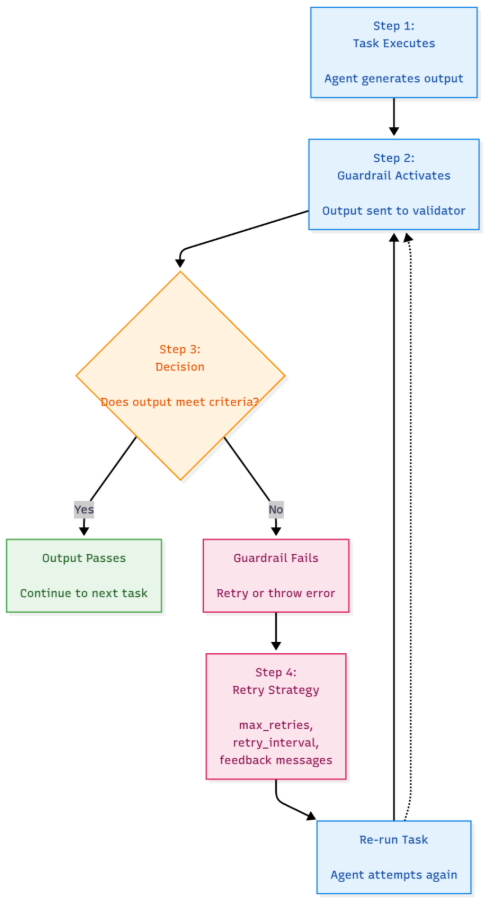
CrewAI’s task guardrails offers a straightforward yet powerful process. The agent executes the task and generates output, then the guardrail activates and receives the output. The guardrail checks the output based on the rules you configured, if the result of the output passes the guardrail check, the workflow continues. If the result of the output fails to pass the guardrail check, the guardrail attempts to trigger a retry or generates an error. You can customize retries by defining the maximum retries, retry intervals, and custom messages. CrewAI logs every attempt and provides visibility into exactly what happened at each step of the workflow. This loop helps ensure the system remains stable, provides the benefit of greater accuracy, and makes for overall more reliable workflow.
Main Features & Best Practices
Function vs LLM Guardrails
Implement function-based guardrails for explicit rules. Implement LLM-based guardrails for possibly subjective junctions.
Chaining Guardrails
You are able to run multiple guardrails.
- Length check
- Keyword check
- Tone check
- Format check
Workflow continues in the case that all pass.
Hallucination Guardrail
For more fact-based workflows, use CrewAI built-in hallucination guardrail. It compares output with context reference and detects if it flagged unsupported claims.
Retry Strategies
Set limits for your retry limits with caution. Less retrying = strict workflow, more retrying = more creativity.
Logging and Observability
CrewAI shows:
- What failed
- Why it failed
- Which attempt succeeded
This can help you adjust your guardrails.
Hands-on Example: Validating a Product Description
In this example, we demonstrate how a guardrail checks the product description before accepting it. The expectations are clear. The product description must be a minimum of 150 words, contain the expression “electric kettle,” and follow the required format.
Step 1: Set Up and Imports
In this step, we install CrewAI, import the library, and load the API keys. This allows you to properly set up all the variables so that the agent can run and asynchronously connect to the tools it needs.
%pip install -U -q crewai crewai-tools
from crewai import Agent, Task, LLM, Crew, TaskOutput
from crewai_tools import SerperDevTool
from datetime import date
from typing import Tuple, Any
import os, getpass, warnings
warnings.filterwarnings("ignore")
SERPER_API_KEY = getpass.getpass('Enter your SERPER_API_KEY: ')
OPENAI_API_KEY = getpass.getpass('Enter your OPENAI_API_KEY: ')
if SERPER_API_KEY and OPENAI_API_KEY:
os.environ['SERPER_API_KEY'] = SERPER_API_KEY
os.environ['OPENAI_API_KEY'] = OPENAI_API_KEY
print("API keys set successfully!")Step 2: Define Guardrail Function
Next, you define a function that validates the output of the agent’s output. It can check that the output contains “electric kettle” and counts the total output words. If it does not find the expected text or if the output is too short, it returns the failure response. If the description outputs correctly, it returns success.
def validate_product_description(result: TaskOutput) -> Tuple[bool, Any]:
text = result.raw.lower().strip()
word_count = len(text.split())
if "electric kettle" not in text:
return (False, "Missing required phrase: 'electric kettle'")
if word_count < 150:
return (False, f"Description too short ({word_count} words). Must be at least 150.")
return (True, result.raw.strip())Step 3: Define Agent and Task
Finally, you define the Agent that you created to write the description. You give it a role and an objective. Next, you define the task and add the guardrail to the task. The task will retry up to 3 times if the agent output fails.
llm = LLM(model="gpt-4o-mini", api_key=OPENAI_API_KEY)
product_writer = Agent(
role="Product Copywriter",
goal="Write high-quality product descriptions",
backstory="An expert marketer skilled in persuasive descriptions.",
tools=[SerperDevTool()],
llm=llm,
verbose=True
)
product_task = Task(
description="Write a detailed product description for {product_name}.",
expected_output="A 150+ word description mentioning the product name.",
agent=product_writer,
markdown=True,
guardrail=validate_product_description,
max_retries=3
)
crew = Crew(
agents=[product_writer],
tasks=[product_task],
verbose=True
)Step 4: Execute the Workflow
You initiate the task. The agent composes the product description. The guardrail evaluates it. If the evaluation fails, the agent creates a new description. This continues until the output passes the evaluation process or the maximum number of iterations have completed.
results = crew.kickoff(inputs={"product_name": "electric kettle"})
print("\n Final Summary:\n", results)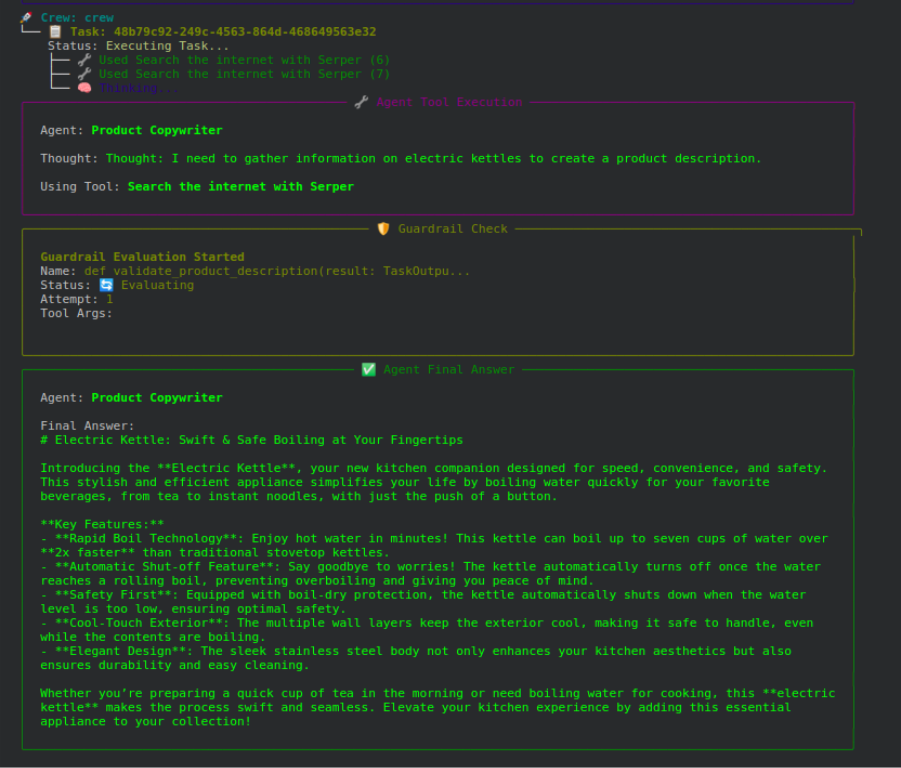
Step 5: Display the Output
In the end, you will show the correct output that passed guardrail checks. This is the validated product description that meets all requirements.
from IPython.display import display, Markdown
display(Markdown(results.raw))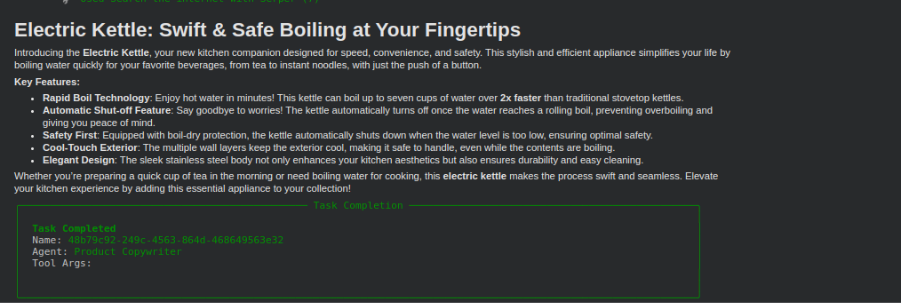
Some Practical Suggestions
- Be very clear in your
expected_output. - Don’t make guardrails too strict.
- Log reasons for failure.
- Use guardrails early to avoid downstream damage.
- Test edge cases.
Guardrails should protect your workflow, not block it.
Read more: Building AI Agents with CrewAI
Conclusion
Task guardrails are simply one of the most important features in CrewAI. Guardrails ensure safety, accuracy, and consistency across multi-agent workflows. Guardrails validate outputs before they move downstream; therefore, they are the foundational feature to help create AI systems that are simply powerful and dependably accurate. Whether building an automated writer, an analysis pipeline, or a decision framework, guardrails create a quality layer that helps keep everything in alignment. Ultimately, guardrails make sure the automation process is smoother and safer and more predictable from start to finish.
Frequently Asked Questions
A. They keep output consistent, safe, and usable so one bad response doesn’t break the entire workflow.
A. Function guardrails check strict rules like length or keywords, while LLM guardrails handle tone, style, and subjective quality.
A. CrewAI can automatically regenerate the output up to your set limit until it meets the rules or exhausts retries.
![]()
Hi, I am Janvi, a passionate data science enthusiast currently working at Analytics Vidhya. My journey into the world of data began with a deep curiosity about how we can extract meaningful insights from complex datasets.
Login to continue reading and enjoy expert-curated content.



